Выходим на борьбу со скликиванием рекламы
Заголовок кликбейтный! Выводов не будет — просто покажу как мониторить те клики, которые Яндекс считает (или может считать) недействительными и возвращает за них деньги.
В этом, как обычно, нам поможет R.
Форд — больная тема для многих. Рекламодатели страдают от скликивания и теряют много денег. Можно обратиться к сторонним сервисам, которые отсекают такой трафик, а можно просто ничего не делать и довериться Яндексу. Яндекс тоже каким-то образом определяет фрод и потом возвращает деньги за «левые» клики.
А правильно ли Яндекс определяет такие клики?
Давайте обратимся к логам Яндекс Метрики, с помощью пакета rym (в очередной раз говорю спасибо Алексею Селезневу).
Приступим. Открываем RStudio и создаем новый проект.
Для начала загрузим необходимые библиотеки:
library(rym)
library(tidyverse)
tidyverse загружаю уже на автомате — тяжело представить, как без него можно что-то делать.
Далее укажем логин и папку с токенами (удобно хранить токены в одной папке — пригодится для других проектов) и номер счетчика Метрики. Если папки нет, то создайте.
login <- "ЛОГИН_МЕТРИКИ"
token <- "АДРЕС_ПАПКИ_С_ТОКЕНАМИ"
counter <- НОМЕР_СЧЕТЧИКА_МЕТРИКИ
Теперь выгружаем данные из Метрики и сохраняем в переменной data:
data <- rym_get_logs(counter = counter,
token.path = token,
login = login,
date.from = "2023-09-01",
date.to = "2023-09-07",
fields =
"ym:s:visitID,
ym:s:lastDirectClickOrder,
ym:s:visitDuration",
source = "visits")
Вот, что мы выгрузили:
ym:s:visitID — уикальный ID визита;
ym:s:lastDirectClickOrder — номер рекламной кампании — понадобится, чтобы оставить только визиты из cpc;
ym:s:visitDuration — продолжительность визита в секундах.
Создаем новую переменную, где будут только визиты с номером кампании, то есть — из рекламы:
data2 <- data %>%
filter(!is.na(ym.s.lastDirectClickOrder))
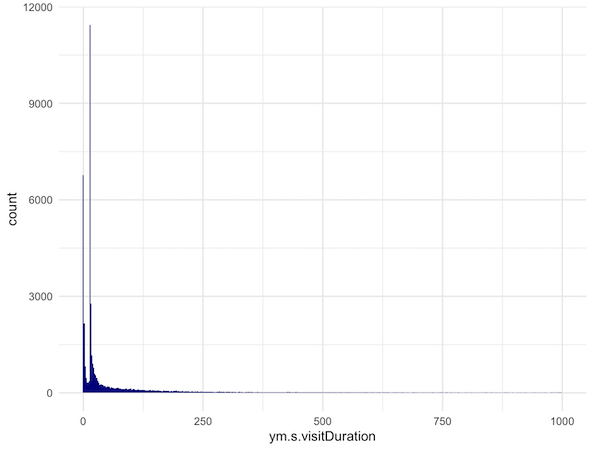
Теперь посмотрим на графике:
ggplot(data2 %>% filter(ym.s.visitDuration<1000),aes(ym.s.visitDuration))+
geom_histogram(bins = 500,fill="darkblue")+
theme_minimal()
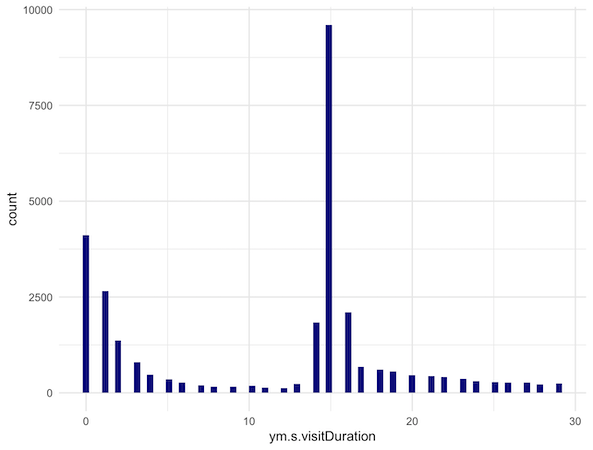
Приблизим — уберем длительные визиты:
ggplot(data2 %>% filter(ym.s.visitDuration<30),aes(ym.s.visitDuration))+
geom_histogram(bins = 75,fill="darkblue")+
theme_minimal()
Посмотрим на количество этих коротких визитов:
data2 %>% filter(ym.s.visitDuration<15) %>% nrow()
В моем случае получилось столько:
[1] 13035
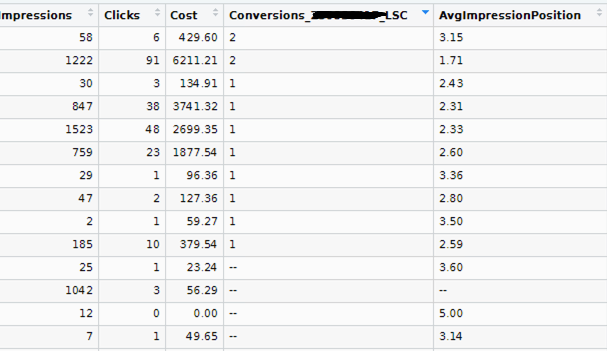
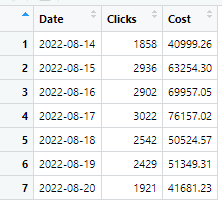
Далее идем в кабинет директа и смотрим статистику:
Очень близко. И такая картина видна по другим проектам. О чем это может говорить? Да ни о чем. Просто информация для размышления. Уверен, что внутри логики Яндекса алгоритмы гораздо сложнее.
В любом случае этот метод может быть полезным — увидите сильное расхождение в цифрах в пользу данных Метрики, то идите к менеджеру в Яндексе. За такое могут вернуть немного денег.
Весь скрипт:
library(rym)
library(tidyverse)
login <- "ЛОГИН_МЕТРИКИ"
token <- "АДРЕС_ПАПКИ_С_ТОКЕНАМИ"
counter <- НОМЕР_СЧЕТЧИКА_МЕТРИКИ
data <- rym_get_logs(counter = counter,
token.path = token,
login = login,
date.from = "2023-09-01",
date.to = "2023-09-07",
fields =
"ym:s:visitID,
ym:s:lastDirectClickOrder,
ym:s:visitDuration",
source = "visits")
data2 <- data %>%
filter(!is.na(ym.s.lastDirectClickOrder))
ggplot(data2 %>% filter(ym.s.visitDuration<30),aes(ym.s.visitDuration))+
geom_histogram(bins = 75,fill="darkblue")+
theme_minimal()
data2 %>% filter(ym.s.visitDuration<15) %>% nrow()